| Putting Privacy in Context... Ian Graham + useful links + This talk: (Word 97) + Presentation (PowerPoint 97) + other talks |
Last Update: 28 June 1999 |
Putting Privacy in Context -- An overview of the Concept of Privacy and of Current Technologies
Dr. Ian GrahamTable of Contents
Introduction {link}
A Definition of Privacy {link}
A Short History of Privacy {link}
The Modern Age: Freedom of Information and Privacy
Laws {link}
The Modern Age: Going Digital {link}
User-Centric Privacy {link}
Personal Privacy and Relationships on the
Web {link}
Next-Generation: Negotiated
Relationships {link}
Summary {link}
Important Technologies and Technical
Issues {link}
Future Technologies {link}
Conclusions {link}
References {link}
The worlds of information and communication are changing, in ways that some people do not yet appreciate, and that none of us truly understand. The latter is so because, over the next 20 years, digital technologies will replace or radically transform essentially every technology of information storage, retrieval and dissemination currently in use. Indeed, it is likely that, transported 20 years into the future, we would barely recognize the everyday tools of communications and data processing.
This social revolution is taking place in part because the new technologies offer unprecedented cost reductions for all three of these just-mentioned factors. But a more important driving force is the new, and largely unexplored opportunity to combine, re-use, and repurpose digital data in ways that were simple not possible with the previous technologies. This will allow us to better understand the underlying processes giving rise to this information, and will (hopefully) give us a better understanding of the natural, physical, and social worlds.
Indeed, the academic community is embracing these technologies as research tools, to improve their ability to understand the world we live in. Similar opportunities exist--and are being embraced--in the commercial and political realms. Increased amounts of digital information, combined with new tools for combining, processing and analyzing these data promise improved efficiencies in business and government process, and a better understanding of these processes as well.
But at what cost? All technologies have unanticipated side effects, and can be used for good purposes or bad: information technologies are no exception. One possible cost is privacy--the concern being that these new technologies will infringe on the ability or right, on the part of an individual, to control their own exposure to the rest of the world or to hide knowledge about themselves. There are many social and technical issues that make this a growing concern, and many possible technical and legal mechanisms that have/are being/will be proposed to provide information protection and define acceptable uses of accumulated information, and protection over the flow and reuse of this information. And, indeed, this is the topic of today's conference.
This paper does not pretend to cover all these issues--subsequent papers in these proceedings will discuss legal and technical mechanisms that can and are being constructed to understand and manage privacy issues, and the administrative processes by which these can be designed and put in place. Furthermore, as I have suggested earlier, I believe that this whole question is still fluid, and that there is as-yet no definitive understanding of how privacy issues will be managed in the next century.
Rather, it is my intention here to provide a cultural and technical framework for thinking about privacy, so that you can appreciate the reasons why privacy is such a compelling issue, and understand the cultural and technical forces that drive the dramatic changes we are seeing. I will attempt to do so by:
Thus, the first part of my paper is a brief review of the 'history' of privacy, based on existing work in this area (the References section at the end of the paper give some suggested readings). As I shall argue, privacy--as far as this conference is concerned--is a relatively new concept and concern. It is also a complex concept, rife with overlapping meanings that vary from society to society and from individual to individual. This has an important impact on policies regarding privacy protection and control in "internationalized" Web applications, and on the construction of appropriate tools for supporting privacy in personalized electronic transactions.
In the next section I attempt to put privacy in context--privacy competes with other social requirements, and can never be dealt with on its own. I will outline some of these competing forces, and explain how they are related.
Finally, I look at the main technical and administrative issues associated with creating "privacy-aware" Web applications.
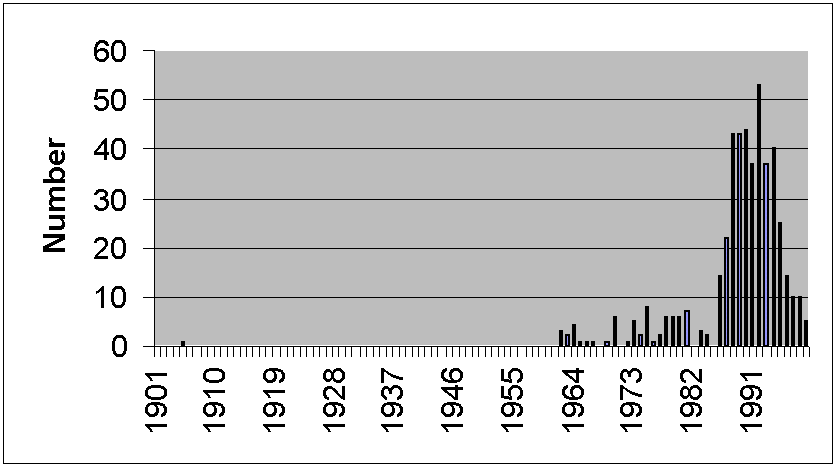
Last, I wish to point out that there is an extensive literature on privacy issues, most of which is quite recent--indeed this paper is only a rough outline of thought on this issue. To demonstrate this I performed a small experiment, by accessing the University of Toronto Library online database and requesting a list of all physical items (mostly books) containing the word "privacy" in the title or item description. Figure 1 shows the number of items published in each year since 1900. Note how almost all text date from the 1970s or later--almost nothing was written on this topic prior to 1960.
Figure 1. Books and other items published in each year since 1900 that are available at the University of Toronto Library and that contain the word "privacy" in either the title or keyword description.
What, exactly, is privacy? To answer this question, I began by taking a dictionary and looking up the definition. This seemingly innocuous task is very useful, because it helps highlight how complex the word "privacy" is, and how difficult it is to discuss "privacy" without an explicit definition of the explicit concept under discussion, and of other concepts related to it.
For example, the Oxford English Dictionary, Second Edition (electronic database version) contains the following definitions for the word privacy (the information listed is somewhat simplified from the actual dictionary entry) [1]:
privacy (15c) (from private) The state or quality of being private.
1.a. The state or condition of being withdrawn from the society of others, or from public interest; seclusion.
b. The state or condition of being alone, undisturbed, or free from public attention, as a matter of choice or right; freedom from interference or intrusion. Also attrib., designating that which affords a privacy of this kind.
2. a. pl. Private or retired places; private apartments; places of retreat. Now rare.
b. A secret place, a place of concealment. (Obsolete)
3. a. Absence or avoidance of publicity or display; a condition approaching to secrecy or concealment. a synonym for secrecy
b. Keeping of a secret, reticence. (Obsolete)
4. a. A private matter, a secret; pl. private or personal matters or relations. Now rare.
b. pl. The private parts. (Obsolete)
5. Intimacy, confidential relations. (Obsolete)
6. The state of being privy to some act; = privity. rare.
It is interesting to note the several meanings: This is the beauty--and horror--of human language! Most of these meanings are rarely used, or obsolete. The meanings of particular interest to use are marked in boldface.
Words generally take on multiple meanings, and privacy is no exception. Even if we ignore the obsolete or rarely used meanings (generally of historical interest only), there are two relevant meanings. It is interesting to look at these, and find examples of "first use" -- that is, examples of the first instance at which the word was used with the associated meaning. This context helps provide a better sense of meaning, and also indicates when that meaning was introduced into the language.
Conveniently, this information is available in the OED, with the following result [1]:
1 b. The state or condition of being alone, undisturbed, or free from public attention, as a matter of choice or right; freedom from interference or intrusion. Also attrib., designating that which affords a privacy of this kind. <one's right to privacy>
1814 J. Campbell Rep. Cases King's Bench III. 81 Though the defendant might not object to a small window looking into his yard, a larger one might be very inconvenient to him, by disturbing his privacy, and enabling people to come through to trespass upon his property.
1890 Warren & Brandeis in Harvard Law Rev. IV. 193 (title) The right to privacy.
3 a. Absence or avoidance of publicity or display; a condition approaching to secrecy or concealment. a synonym for secrecy
1598 Shaks. Merry W. iv. v. 24 Let her descend: my Chambers are honourable: Fie, priuacy? Fie.
1641 Wilkins (title) Mercury: or the Secret and Swift Messenger. Shewing how a Man may with Privacy and Speed communicate his Thoughts to a Friend at any Distance.
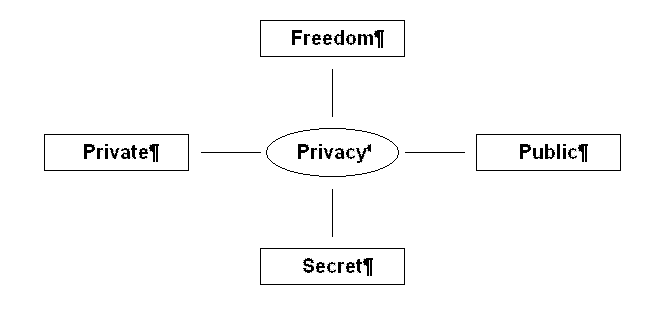
Thus, although the word came into existence in the 15th century, the meaning that is of interest to us (1 b) did not arrive for another four hundred years. This tells us something quite interesting --that privacy, as we understand it, is a relatively new concept. We also note that the definitions depend on an appreciation of the concepts of "public", "secret", and "freedom." As we shall see, it is impossible to separate these linked concepts--and, indeed, no privacy policy can ignore issues of public versus private rights and obligations, secrecy, and freedom of information. Figure 2 summarizes these four issues:
 >
>
Figure 2. Illustration of the relationship between "privacy" and the four related concepts of private, public, freedom (of information), and secret. Privacy has no meaning unless information can be kept "secret," while concerns for privacy are not relevant unless there are well-defined private and public realms.
These issues will be discussed in a later section. The questions for now are: how did this new meaning evolve in a broad, social context; and how does this affect our current appreciation of the issues surrounding privacy? These questions are tackled below.
Given a time frame and an acting definition, we can now examine history y. By looking at the cultural and social history of privacy (see, for example, [2,3]), one finds that "privacy" is simply not relevant in most pre-technical, non-democratic societies. For example, in nonliterate societies there is no privacy in the modern sense: privacy is only relevant in the sense of meaning 2 a defined above, as a physical retreat to a location private from the community.
This is the case because the modern view of "privacy" requires a well-defined separation between public and private realms. Pre-literate societies do not provide such a distinction: such societies are essentially communal and largely unstructured--everybody knows everybody else, and everything is everybody's business. As a result, there is no clear social boundary between the "private" and "public". Indeed, it is clear that "privacy" has no meaning except with reference to a formally structured organization (such as a society, or company) that has a "public" component with power that can infringe upon an individual's "private" realm.
Indeed, the concepts of "public" and "private" are well-developed in societies such as ancient Greece or China, and there is a reasonable record of writings on the topic of "public" and "private" behavior. However, "privacy" is never discussed as an important issue of social policy, other than in terms of minimalist property rights.
As societies continued to become more structured, one might have expect privacy to soon become an important social issue. However, this did not happen until very recently (19th century). Instead, history shows most societies evolving more and more powerful centralized "public" realms (the Catholic church, imperial authority in China, European royalty) with broad powers of "public authority." These authorities served to provide stability, and order to the society, with also to preserve the state itself.
But there was no equivalent push for social rights such as privacy. In part this was because power was concentrated in the ruling classes, so that there was little opportunity for "general" issues to evolve. At the same time, the generally-accepted social foundation of most societies (e.g., the Church and royalty in the West) specifically denied rights to the individual. Society had two strata: the state on top, and the peasants below, with accepted dogma implying that truth and justice flowed, by divine nature, down from the state. Thus there was no assumption of individual rights, and hence no reasons to even think of a right to privacy.
The impetus for strong "private" realms likely arose from 18th century changes in the power structure within Western society. In this context, there were two particularly important changes that affected the relationship between individuals and the state: the concept of individual freedom that arose out of the work of the philosophers of the "Enlightenment" (late 17th century), and the growth of a wealthy mercantilist class (18th century) with economic power independent of the state.
The "enlightenment" introduced an enormous change in the perception of an individual's place within society. Although many ideas that came out of this era, perhaps the most important from our perspective was the idea that human experience was itself the foundation of human understanding of truth, with external authority being less important than personal experience.
Note how this "breaks" the rationale of top-down "public authority" as the controlling force in a society. Up until the enlightenment, the individual was morally subsumed, by the underlying social assumptions of the day, beneath the society in which they lived--public authority had both the obligation and right to dictate any detail of the lives of individuals. The philosophers of the enlightenment, however, say that each individual had the unique ability and right to determine truth, and that authority should be questioned. This then eliminates the underpinnings of the top-down social order of the existing society, and hence the legitimacy of the existing social order.
The second blow was the appearance and growth of a wealthy mercantilist class, and of the bourgeoisie. These groups, distinct from the church and the ruling royalty, grew over time to control larger and larger portions of the economic power of society. However, with economic power came political power, and with political power came privilege and rights. Thus, to preserve their economic well being, these groups pushed societies to incorporate legal and political protection against unbridled actions by the "public" state that would affect their economic power base. Political protection came via their inclusion of the bourgeoisie within the political system, while legal protection came via laws for arbitrating commercial disputes, and laws enforcing legal protection of property and other private assets. In a sense, these property laws were the first manifestation of privacy protection, providing freedom from arbitrary seizure of private assets, and the ability to control activity on private property free of arbitrary state interference.
Of course, these issues were dealt with differently in different countries (and in some countries, much later than others). In particular, each country's history led it to a different interpretation of the appropriate boundary between personal and state rights. One can even argue that some countries (such as the United States) were formed due to a dispute over this boundary. Thus, it is not a surprise that laws and attitudes varied (and still vary) widely between countries.
The Modern Age: Freedom of Information and Privacy Laws
With the majority of government and corporate assets consisting of things (property, machinery, etc.) property and asset protection rules were largely sufficient. However, during the 1960s, information started to become a important asset, as computer databases began to archive large amounts of personal and general governmental data (for example, for tax calculations, census analysis). Such databases led to unprecedented concentration of information in easy-to-access and easy-to-use forms.
At the same time, there was growing awareness of the amount of information held by governments, and a growing sentiment that most of this information should be publicly accessible--in most cases this information was considered state property, not open to public scrutiny. This concern led, in many countries, to freedom of information legislation, which provided mechanisms for public access to government (and, in some cases, corporate) information. Such legislation makes allowances for the natural restriction of access to sensitive information, such as "state" secrets, or private deliberations. In particular, access is typically refused to information that would result in an invasion of personal privacy.
Not all countries have freedom of information laws (The US freedom of Information Act was passed in 1966, similar legislation in Canada in the early 1980s. Sweden's Freedom of Press act, however, dates back to 1766). Furthermore, each piece of legislation has different access rules, owing to different nations' sensibilities regarding what is considered public and private. For example, in Sweden, aggregate information from an individual's tax return (i.e., gross and net salary, tax paid) is public information, available to anyone. Citizens from many other countries would consider such public access a distinct violation of their right to privacy!
At the same time, there arose "invasion of privacy" concerns due to possible misuse of personal information stored in these databases. This concern is actually implicit in most freedom of information legislation, which largely forbids the release of information that would violate an individual's right to privacy. However, freedom of information legislation generally placed no specific restrictions on how information could be used within government (or within a company), and as more and more information was being accumulated, concerns about possible misuse grew. Many countries saw a need for additional legislation or regulation to regulate how information could be gathered and used, and to provide ways by which an individual could confirm that information about them was accurate.
Legislation for protecting personal privacy is often discussed under the category of data or privacy protection, and many governments have implemented relevant laws. Such laws are designed to govern the appropriate use of collected information, by both government and private organizations, and to specify access mechanisms by which an individual can view information collected about them. In Canada, bill C-54 is, among other things, intended to be a major step in implementing these mechanisms with the force of law.
It is important to note that such laws are new and evolving, while attitudes towards privacy protection and freedom of information still vary significantly between nations. Even within countries, laws regarding privacy often vary between regions, depending both on the responsibilities afforded the different levels of government and the degree to which the government decides to offer protections. For example, in Canada, provincial privacy laws are quite different from province to province.
This last section briefly summarized some general trends. The next section will look in more detail at how new digital technologies are affecting our understanding of privacy issues.
The recent explosive growth in interest in privacy issues is due to four related factors:
Digital records have been rapidly growing over the last twenty years, as more and more business processes have been computerized. However, only been in the last few years has it been easy to share this information with others, either inside or outside an organization. This is largely due to evolving "open" standards for data representation, that make it much easier to interpret digital data provided by others, and cost reductions in these technologies. Last, new "data mining" tools make such combinations enormously beneficial, as they let researchers o analysts view the information in new ways, and determine trends or patterns that have important commercial applications.
The growth of corporate databases in the 1970s led to realization that some forms of government-imposed protection were in order. Indeed, there have been several stabs at legislating appropriate use of information gathered by private companies. For example, the United States Cable Communications Privacy act of 1984 prohibited a cable system from gathering information that might be considered "personally identifiable," and provided rules by which information could be released [4].
Interestingly enough, there have also been attempts by government to obtain information from "private" corporate databases. An example of interest to academic institutions took place in the early 1980s. The FBI, through a "Library Awareness Program," began asking librarians to search through their records to locate library patrons who had requested books considered dangerous--in this particular case, the FBI was searching for clues to the identity of the so-called "Zodiac" killer. Librarians who refused to do so (note that there was no legal obligation to comply with this request), were themselves added to a list of those of concern to the FBI [5].
It is difficult to protect against such requests: moralistic arguments, combined with mild threats, are usually sufficient to coerce compliance from most individuals or businesses. Within the library community, a consensus arose that the best protection against such requests was to simply not gather this information, thereby reducing the ways in which staff could be pressured to provide it. For a library this is a simple decision, as management does not need to know the identity of a reader once a book is returned. Thus, most current "patron" databases discard this information when a book return is registered. For cases where usage patterns are of interest, systems are designed to anonymize the data. That is, once the book is returned, the identity of the reader is discarded, and only the fact that the book was checked out is retained.
This story illustrates that systems can (and probably should) be designed to gather only information that is needed, and in such a way that information is automatically discarded when no longer required. Not also that in the case of library databases this was a conscious design decision, designed explicitly to preserve patron privacy and based on a requirements analysis. For any organization, the software implementation will depend on a definition and analysis of the gathered information, possible uses of this information, and concerns about misuse and appropriate use. Note that the final software implementation can be designed to explicitly discard possibly useful information--as in user reading patterns at a library. What is kept or discarded will depend on the culture of the company, imposed legal requirements, and on the difficulty of the software design.
Note too that this is a policy issue, but one where significant implementation details occur in software. That is, the software design merely implements higher-level policy decisions regarding information gathering and usage. This means that policy issues should be carefully thought through before software systems are developed, and furthermore that the software design should allow for changes to privacy policy if public demand (or legislation) calls for it. The implications for a company implementing Web-based commerce are clear:
Of course, most projects are not implemented in this way. However, as systems become larger, and as legislation changes, organizations run the risk of high-cost software and data conversion efforts should the software and archived data not lend itself to easy modification.
The preceding discussion has focussed on privacy with respect to the relationship between individuals and large institutions, such as government. In this case, the type of information accumulated about people has traditionally been well defined (and, indeed, is largely mandated by regulation). Thus it makes sense to talk of "one size fits all" privacy policies and/or legislation, as has been the case to date.
For example, when applying for a bank loan or mortgage, the types of information required by is largely standardized from bank to bank, as are the allowed uses of the information by the bank. Furthermore, an individual can negotiate certain aspects of the loan (interest rates, time frames, etc.) before deciding which institution will provide the loan, only then providing the required private information. Completing tax returns is an even more uniform example--everyone fills out the same information, with the knowledge that the information is supposedly well protected by government privacy policies.
However, information disclosure and privacy are not just policy issued--they are often also individual, personal decisions. In daily life, and in business or in personal relationships, each individual decides what type of information to reveal about themselves. In other words, people invoke different levels of privacy depending on the party they interact with, balancing the advantages gained by releasing information against the possible risks. For example, we provide far more information about ourselves to the government, a bank, or our spouse, than to a pollster, a corner store, or a person we just met in a bar. These choices are based on the perceived advantages of the exchange, and the risk of inappropriate use of the information we provide.
When providing personal or other "private" information, each individual develops and evaluates a trust relationship with the other party. Via discussions in a (typically) private environment, each individual will determine what information to reveal, based on the perceived trustworthiness of the other party, and on the expected benefits derived from revealing the information. Trust is a complex issue, and traditionally has been based on the reputation of a company (or individual), and, in the case of individuals, on the personal rapport that develops between them.
Such issues have traditionally been outside the scope of concern of privacy regulation, since few companies collected extensive information about customers, and had insufficient tools to make effective commercial use of what information they did collect.
Today, however, more and more information is automatically incorporated into databases, to the point where social scientists often refer to "digital personas"--the digital impression of people onto electronic systems. Today such information is gathered via mechanisms such as membership subscriptions (e.g., magazines), specialty service cards (e.g. Air Miles) or reservations/bookings (e.g., hotel, air). This information is most commonly used for traditional marketing, such bulk mail, or for tracking product/service preferences.
In most cases individuals have a common understanding of firms that they trust, an awareness of the information they provide (as they provide most of it directly) and a perceived (if perhaps inaccurate) understanding of how the information will be used. Web applications, on the other hand, tend to obscure the first two issues, while opening up new opportunities for data use.
Personal Privacy and Relationships on the Web
On the Web, data mining and reuse have become central to most Web-based business ventures. This is because a major strength of Web commerce is the ability to provide service tailored to individual customers. Indeed, most Web-based businesses store and use enormous amounts of information about their customers to provide effective and competitive service. Furthermore, the customer information they gather, which itself is often in easy-to-reuse formats, is in itself a valuable asset that can itself be traded or sold.
However, all of this is contingent on gathering user information. Doing so requires requires establishing a trust relationship between the company and its customers or business partners. Open privacy policies, and the ability to deal effectively and promptly with user inquiries, are critical to establishing this relationship.
There are four issues that come up when dealing with privacy and Web commerce:
In the last section of this paper we review the relationship between these issues and relevant technical and systems architectural components. Other papers in these proceedings will investigate how these issues can be integrated into operational policy.
Next-Generation: Negotiated Relationships
The implicit long-term goal of Web site personalization is the establishment of negotiated relationships with customers. A negotiated relationship is one in which the two parties negotiate for a range of services based on the information and financial contributions of each party. For example, a customer may choose to not divulge their mail address, in exchange for non-customized service. Alternatively, they may offer to provide both an email address and other identifying information, and perhaps pay a monthly fee, to obtain additional, customizable services.
At present, this must be done by hand by each user--they must personally check the service offered, and determine what level of service they wish to use. In many cases, this is the most time-consuming and complex stage in attracting new customers, and hence the most likely inhibitor to new subscribers. Thus, current systems have very little flexibility to negotiate different relationships.
However, this is clearly the wave of the futur, as it provides the greatest advantage over traditional business operations, and the greatest advantage over Web sites not offering equivalent service. Of course, it is clear that such a range of service offerings makes privacy issues more complex. For example, a company could offer additional service in exchange for permission to use a customer's email address in marketing efforts. But, what specifically would that mean? As the range of possible "privacy policies" grows, it becomes more and more difficult to understand the implications of specific choices.
We will revisit this issue in the last part of this paper, when we discuss some of the technologies used to implement privacy issues in commercial Web sites.
This brief history leaves us with several interesting and useful observations.
Every commerce system must be designed to deal with the issues relevant in a particular implementation--the situation is simply more important to Web commerce due to the increased quantity of information and the ability to customize to individual users. For example, an international commerce site must allow for national variation in attitudes to privacy, as well as for differing legal requirements. Other sites may be particularly concerned with proof of identity, so that confidential information is not divulged to other parties. Finally, data usage policies must be well known and publicized so that parties can understand the relationship with their partners.
Important Technologies and Technical Issues
As mentioned earlier, Web commerce applications should take privacy issues into account during the design phase of the application. This ensures that the designers are aware of the constraints imposed on communication and information storage/retrieval by legislation (if relevant) or by the details of the chosen privacy policy. This will determine how data and communication encryption, security issues, and database design are implemented--decisions that can be very expensive to change if not implemented correctly at the outset.
Note that security and encryption are themselves complex technical topics. The material here is simply a rough overview: additional useful information is found in [8].
Data Security: Firewalls, Data Encryption, and Communication Encryption. Once information is gathered, an organization will need a way of keeping it secure. This task has both technical and administrative components: technically, the system must provide appropriate network (and physical) security and access control, to ensure that private information is kept private. An example where this failed is found in the recent Air Miles fiasco, but there are have been many, less publicized incidents. Indeed, just about every institution can look inside itself to find examples where data security has been compromised.
Typical data security technologies include firewalls (to exclude external users from your internal network), data encryption (to make stolen data useless), and communication encryption (so that data in transit cannot be intercepted). Behind this lie a well-defined network security policy, designed by security experts. Such policies should take into account concerns for privacy issues, so that particularly sensitive data is adequately protected.
At the system level, the computers and the application software must be designed to restrict access to authorized users, or to authorized software agents (e.g., the agent that assembles email addresses for bulk mailings). Note that systems supporting "negotiated relationships" will need to provide different levels of access control and security depending on the data. For example, if some users have authorized re-use of their email addresses while others have not, the system must be designed to know of these options, and handle them accordingly.
Systems should also have proper transaction logging and audit trails that monitor activity of the database and of user (or agent) access. Something will inevitably go wrong, and these tools will let the network and system administrators find out what went wrong, and why.
Lastly, data security is a human resources/administrative task--most security breaches occur due to unimplemented policies (procedures are not accurately followed) intentional theft or sabotage. It is important that administrative policies and rules reinforce and augment any software and hardware security tools.
Communications Security. Information is not private if it is communicated via publicly accessible means--which is the case for all unencrypted Internet traffic. Thus, if there is concern over information contained in communication between individuals and an organization or between individuals but moderated by a company, technology should be employed to ensure the communication is confidentiality.
There are several ways to do this. When sending or receiving Web pages or newsgroup messages, low-level packet encryption of the communications line (e.g. Secure Socket Layer (SSL) or Private Communications Technology (PCT) software) encrypts the underlying communications channel. This ensures that the message (a Web document, submitted HTML form data, newsgroup posting, or mail message communicated to a mail server) cannot be intercepted and read.
This may be insufficient, however, if the message is stored somewhere (either at the destination or in transit), as the message itself is unencrypted--only the communications channel is protected. Thus, if messages are stored or cached the application must make sure that the received data is itself encrypted for storage, or destroyed.
Internet mail systems support message encryption--indeed, very little mail is sent using low-level SSL-style encryption. Message encryption encrypts the message prior to sending it via standard, possibly unencrypted Internet mail protocols. Thus, even if the message is intercepted, it cannot be read. In this case, low-level encryption is not needed, and the information can be sent via regular Internet mail systems. Note, however, that a mail message could be intercepted, and in some cases a "forged" message substituted in its place. Low-level SSL encrypting eliminates this possibility.
There are three common forms of email message encryption: Pretty Good Privacy (PGP), Privacy Enhanced Mail (PEM) and Secure MIME (S-MIME). All these mechanisms allow reliable data encryption (but using different approaches).
Again, once received messages are decrypted, they can be read by anyone. Thus, if they are to be stored locally, it may be important to use encryption to ensure that they are unreadable if stolen. It may be sufficient to simply delete the raw data once the transaction is complete. Failure to do so has causes several of the "security" failures of several common E-commerce systems.
Of course encrypting a message is not the same as proof of identity for the author--an encrypted message can come from anybody. Proof of identity is the second important aspect of any commercial transaction, and some digital ways of providing such proof are discussed next.
Identity Verification: Digital Certificates. For many transactions it is important to know the identity of the party you are dealing with. For example, if you are a consumer about to purchase an expensive product via the Web, you will want to be sure of the identity of the company you are dealing with. Conversely, the company may want proof of identity of the customer--to verify, for example, that the customer has permission to access certain information in the company's system, or to exceed a defined credit limit.
For low-security systems, identity of a Web-accessed resource is typically assumed from the URL of the resource (for example, www.ibm.com is probably IBM Corporation). User identity, on the other hand, is generally "proved" by the user logging in with defined usernames and passwords. In general this username/password is originally generated by the commerce system when the user creates an account.
Note that neither of these approaches provides actual "proof" of identity. A URL can be spoofed, so that a malicious computer expert could redirect unsuspecting customers away from the real location, and to another machine. A user, on the other hand, can create an account using any name/identity they choose--a company has, in general, few ways of authenticating the identity of a person creating an account. Furthermore, it can be easy to steal a person's username and password--particularly if the underlying messages are not encrypted when sent via the Internet--so it can be easy for a third party to obtain this information, and masquerade as someone else.
There are technologies that can help. Encryption technologies such as SSL include digital certificates for each Web server (purchased with the server, renewable and with a finite lifetime), that let a remote user verify that they are indeed talking with a particular Web server. Every browser checks with a trusted third party to verify that the certificate is valid, and informs the user if there is a problem. Thus a user can always be sure, if they are using an SSL-secured connection, that they are communicating with a company that bought and registered the indicated certificate.
The converse is also possible--browsers can have their own certificates, to verify the origin of the communication. Similarly, the higher-level email encryption protocols (PGP, S-MIME) support digital message signing. With this mechanism, the author can digitally sign a document such that the recipient can ensure that the document was composed under the authority of the signing certificate, and also that the message was not tampered with.
Unfortunately, this mechanism is rarely used at present--each person needs to purchase a certificate, and most do not bother to do so. Furthermore, such certificates are only as trustworthy as the user's computer--if person A can digitally sign mail using their mail client, but their machine is also accessible to person B, then person B can easily masquerade as person A. Indeed, digital identifiers, as presently implemented, are only as secure as the machines from which signed documents are sent. At present, this somewhat limits the reliability of these technologies as "proof of authorship," although it is certainly better than receiving unsigned data. It also limits masquerading to a single machine, as opposed to any machine on the Internet, which is admittedly a significant improvement.
Figure 3 illustrates in a general way the relationship between security/privacy issues (which will be determined by policy) and the related technical/administrative issues that appear in a real implementation
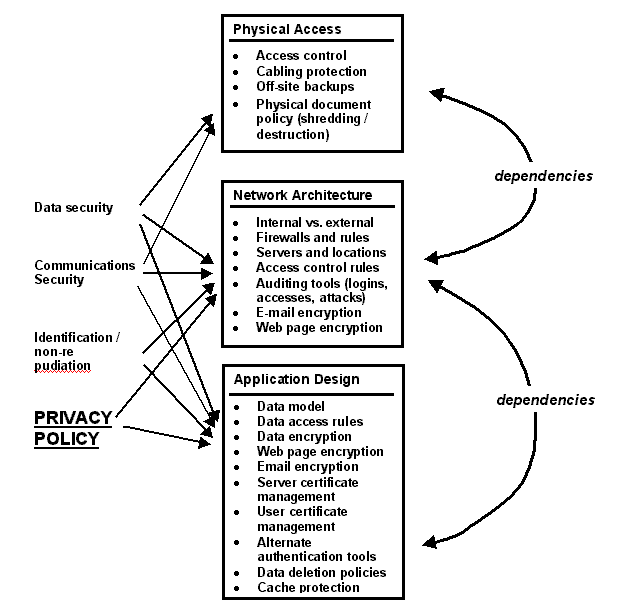
Figure 2. Schematic showing the relationships between privacy/security issues (left), and implementation decision points. The arrows on the right illustrate the interdependencies found in any implementation.
It is interesting to note that portions of Bill C-54 would make digital signatures a legal means of identification (or, better stated, non-repudiability) of the sender.
When a visitor contacts a resource requiring "private" information, they generally decide, based on a number of factors, which information they feel comfortable providing. At present, such information is provided via fill-in forms. But, as mentioned previously, this stage of negotiation is the most complex "entry" point to a service. Unfortunately, complex transactions tend to scare away potential customers, simply because of the tediousness of wading through page after page of privacy policy statements, personal information questions and fill-in forms.
Much of the information requested, and statements about the intended use of the provided information, are relatively straightforward. Indeed, there is a lot of repetition from site to site, with most sites asking for the same sorts of information, and in return offering similar privacy/information use policies.
Ideally, it would be nice if much of this "negotiation" could be automated. For example, upon accessing a Web site, a Web browser could receive a machine-readable "privacy policy" statement, describing the privacy policy and the types of information the site is requesting. The browser could then read a set of user-defined privacy preferences, and determine which information can be immediately sent to the server, which should not be sent, and which should be sent at the option of the user.
To make this work requires a well-defined language for expressing privacy preferences and policies. This is the long-term goal of a World Wide Web Consortium working group known as the Platform for Privacy Preferences (or P3P) project. The goal of P3P is to establish an application-level language for publicizing privacy policies and for negotiating the release of person information to sites, depending on the site policies. The stated goal of P3P is:
The P3P specification will enable Web sites to express their privacy practices and users to exercise preferences over those practices. P3P products will allow users to be informed of site practices, to delegate decisions to their computer when possible, and allow users to tailor their relationship to specific sites. Sites with practices that fall within the range of a user's preference could, at the option of the user, be accessed "seamlessly," otherwise users will be notified of a site's practices and have the opportunity to agree to those terms or other terms and continue browsing if they wish [6]
Unfortunately, P3P is still a work in progress. Furthermore, many commercial projects/services are already underway designed to address some of the issues being addressed by P3P [7]. However, understanding the design parameters of P3P are useful for understanding the issues of software-mediated privacy negotiation, independent of the biases of any current software implementation.
This short paper has provided a brief history of the concept of privacy, and tried to show how this rather new concept is evolving rapidly in the latter half of the 20th century. In doing so, it demonstrated that there are several competing issues to address if understanding privacy issues, including culture, law, proof of identity, and trust. This section also demonstrated that the negotiation of relationships also requires a clear understanding of privacy policies and a fine-grained approach to information exchange (so that the exchange can be tailored to the individual).
The second part of the paper briefly reviewed some of the technical issues that come up when dealing with privacy and information security issues. This brief review touched on issues such as data and communication encryption, network and application architecture, and the important roll of policy decisions in the implementation of the underlying design.
In the beginning of this paper, I noted how much had been recently written on privacy issues. Reference [9] provides a useful summary of some printed and Web-accessible resources, should you wish to read further on this most interesting issue
1. Oxford English Dictionary, Second Edition, Oxford University Press, http://www.chass.utoronto.ca/chass/oed/oedpage.html (University of Toronto access only)
2. Privacy: Studies in Social and Cultural History, Moore, Barrington, Jr. Pantheon Books, 1984. This book provides an excellent review of the history and sociology of privacy prior to the 20th century.
3. Technology and Privacy: The New Landscape, Agre, Philip E., and Rotenberg, Marc, eds. MIT Press, 1998. This contains a collection of papers summarizing some of the ramifications of new technology on privacy and freedom of information issues.
4. http://www.conwaycorp.com/electronics/services/privacy_notice.html (Conway Corp. statement regarding compliance with the Cable Communications Privacy Act)
5. American Libraries, 21/3, pp245-248, 1990 (March)
6. http://www.w3.org/P3P/ (Platform for Privacy Preferences overview)
7. http://www.w3.org/P3P/implementations (A listing of privacy and personal profiling software services: such as DigitalMe, Firefly, and others.)
8. E-Commerce Security: Weak Links, Best Defenses, Anup K. Ghosh, John Wiley and Sons, 1998
9. List of other Privacy-related books, articles, and Web resources: http//www.iangraham.org/talks/privacy/privacy-links.html
| Putting Privacy in Context... Ian Graham + useful links + This talk: (Word 97) + Presentation (PowerPoint 97) + other talks |
Last Update: 28 June 1999 |